智能体网页信息采集
真实工作流
网页采集场景通常不是长期稳定的大型爬虫,而是临时、低频、字段经常变化的信息整理任务。
| 维度 | 真实情况 |
|---|---|
| 触发点 | 竞品调研、招聘信息汇总、企业公开信息收集、行业资讯整理 |
| 现有材料 | 目标网址、字段要求、筛选条件、历史表格或输出模板 |
| 卡点 | 网站结构不统一,手动复制容易漏字段,传统爬虫开发成本不划算 |
| DesireCore 介入 | 网页信息采集智能体浏览页面、提取字段、保留来源链接并输出表格 |
| 验收结果 | 用户拿到可抽查的数据表,再按合规要求确认采集范围和数据用途 |
可以处理哪些工作
网页浏览
- 多页面并行:同时打开多个网页,批量采集
- 动态内容处理:支持 JavaScript 渲染页面,等待内容加载
- 登录态保持:在你已授权的账号范围内访问需要登录的页面
- 访问频率控制:按目标网站要求控制访问节奏,避免造成负担
字段提取
- 自然语言指令:"提取这个页面的产品名称、价格和评分"
- 表格数据识别:自动识别网页表格,完整提取行列数据
- 列表内容采集:新闻列表、商品列表、搜索结果批量获取
- 嵌套数据处理:详情页链接自动跟进,采集完整信息
结构化输出
- Excel / CSV 导出:标准表格格式,便于后续分析
- JSON 格式:对接数据库或其他系统
- 自定义模板:按需定义输出字段和格式
- 增量更新:对比历史数据,仅输出变化部分
定时任务
- 周期性采集:每日、每周自动执行
- 变化监控:价格变动、内容更新实时提醒
- 历史记录:保留采集历史,支持趋势分析
工作流控制点
| 阶段 | 需要确认的细节 |
|---|---|
| 范围确认 | 目标网站、栏目、页数、字段和筛选条件是否明确 |
| 合规检查 | 是否允许采集,是否涉及登录态、个人信息、版权内容或网站禁止条款 |
| 抽取规则 | 字段名称、价格单位、时间格式、缺失值处理和来源链接是否保留 |
| 数据清洗 | 去重、标准化、异常价格、空字段和重复商品是否处理 |
| 输出校验 | 抽样检查若干条记录,确认字段没有错位或遗漏 |
| 持续维护 | 页面结构变化时重新校对规则,定时任务要保留采集日志 |
会用到的 DesireCore 能力
- 桌面自动化 / GUI 控制:必要时通过浏览器页面操作、截图识别和表单交互完成采集
- 定时巡检:周期性检查价格、公告、招聘信息等变化,有变化再通知
- 安全审计:保留采集来源、执行记录和输出文件,方便后续追溯
典型使用场景
场景一:官网商品采集
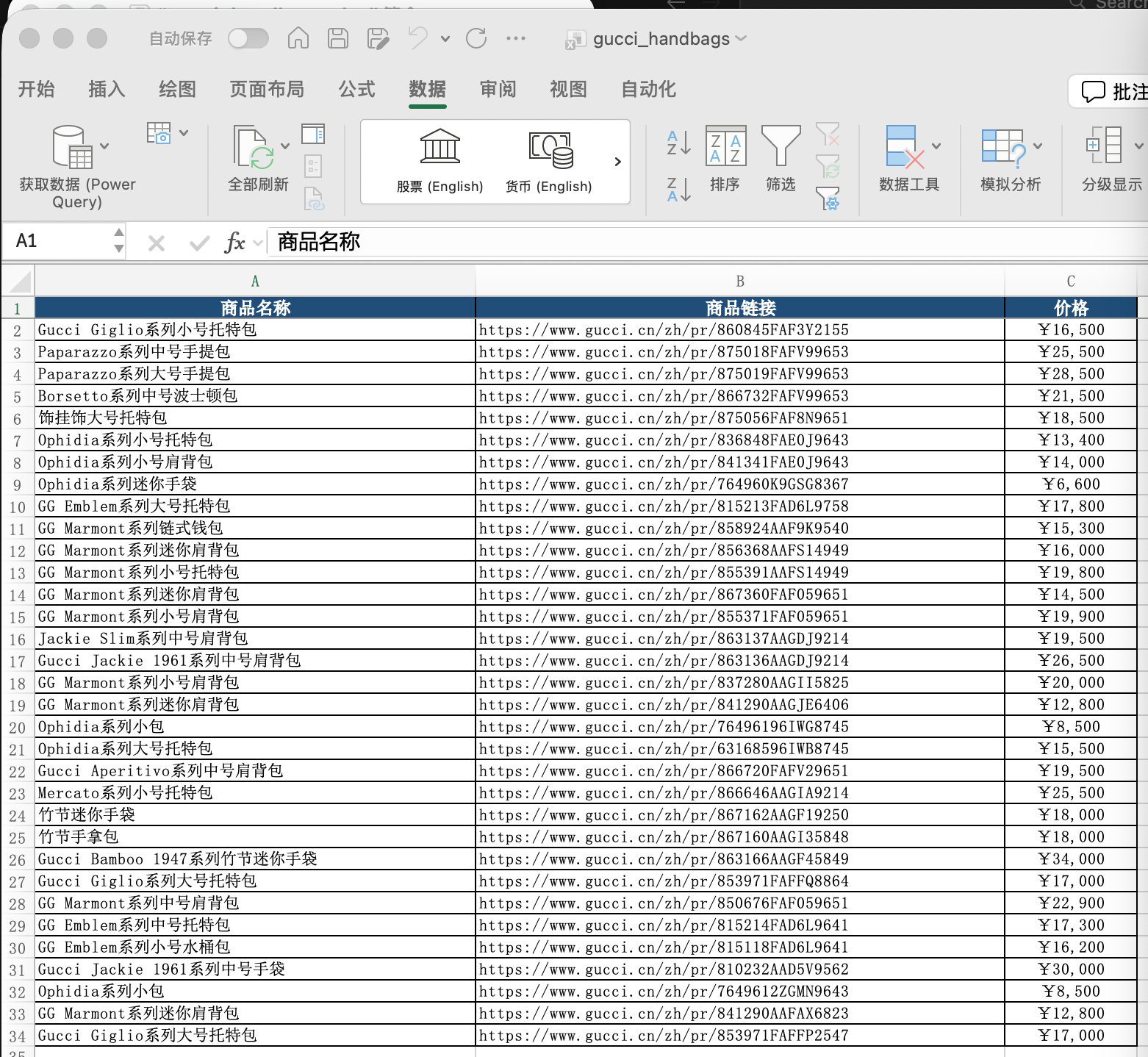 文件地址:./assets/web-scraping/gucci_handbags.xlsx
文件地址:./assets/web-scraping/gucci_handbags.xlsx
📁 输入
├── 目标网站:gucci.cn(Gucci 中国官网)
├── 采集范围:手袋品类全部商品
└── 用户指令:"采集 Gucci 官网所有手袋的名称、价格和链接"
⬇️ 智能体处理后
📊 输出:gucci_handbags.xlsx(33 件商品)
├── 商品名称
│ ├── Gucci Giglio系列小号托特包
│ ├── Paparazzo系列中号手提包
│ ├── Gucci Jackie 1961系列中号手袋
│ └── ... 共 33 款
├── 商品链接
│ └── 每款商品的官网详情页 URL
└── 价格
├── 价格区间:¥6,600 ~ ¥30,000
└── 结构化数据,可用于后续对比分析
场景二:行业资讯聚合
📁 输入
├── 行业媒体网站(10 个)
├── 关键词过滤规则
└── 用户指令:"采集今天的 AI 行业新闻,按重要性排序"
⬇️ 智能体处理后
📊 输出
├── 今日资讯汇总.md
│ ├── 重要新闻 TOP10(含摘要)
│ ├── 按主题分类整理
│ └── 原文链接
├── 关键词词云图
└── RSS 订阅源(可导入阅读器)
场景三:企业信息收集
📁 输入
├── 目标企业名单(50 家)
└── 用户指令:"收集这些公司的基本信息、融资情况、主要产品"
⬇️ 智能体处理后
📊 输出
├── 企业信息库.xlsx
│ ├── 公司名称、成立时间、注册资本
│ ├── 融资轮次、投资方、融资金额
│ ├── 主营业务、核心产品
│ └── 官网、联系方式
├── 企业画像卡片(PDF)
└── 数据来源标注
场景四:招聘信息汇总
📁 输入
├── 招聘平台(3 个)
├── 职位关键词、城市、薪资范围
└── 用户指令:"找出符合条件的产品经理岗位"
⬇️ 智能体处理后
📊 输出
├── 职位清单.xlsx
│ ├── 公司、职位、薪资、要求
│ ├── 发布时间、申请链接
│ └── 匹配度评分
└── 薪资分布分析图
效率对比
| 指标 | 手动采集 | 传统爬虫脚本 | 网页信息采集智能体 |
|---|---|---|---|
| 采集 100 条数据 | 耗时且容易漏项 | 开发完成后较快 | 适合临时或字段经常变化的采集任务 |
| 技术门槛 | 无 | 高(需编程) | 低(自然语言) |
| 网站适配成本 | 无 | 高(每站写代码) | 可通过描述字段快速调整 |
| 维护成本 | 持续人力 | 高(网站改版需更新) | 需要按页面变化重新校对 |
| 非结构化内容 | 可处理 | 困难 | 擅长 |
| 合规性 | 人工判断 | 需配置 | 仍需你确认网站条款和数据用途 |
使用须知
⚠️ 合规提醒:
- 请遵守目标网站的 robots.txt 和使用条款
- 控制采集频率,避免对目标网站造成负担
- 仅采集公开可访问的信息
- 采集涉及个人信息、账号内容或受版权保护内容时,请先确认授权和数据使用范围